
|
|
6. データ型
今回が「 learn C」の最終回になります。
ここでは今まで説明したこと以外に知っておくと便利なことや構造体の説明をしたいと思います。特に構造体は次回の『 learn ObjC 2.0 」への布石になると思います。
プリミティブ(基本型)
文字を表す char 型、整数を表す int 型、浮動小数点数を表す float 型、倍精度浮動小数点数を表す double 型などを基本的な型もしくはスカラー値などと呼びます。ざっと眺めて分かるとおり全て数値を表すものだということが分かります。文字型 char は内部的には文字を文字コードという数値で保持しています。C言語では"文字列"は"文字"を表す char 型の配列として格納します。
なお変数を宣言するときには、まずデータ型を指定して宣言する変数をカンマで区切って複数を1度に宣言することもできます。
int a, b, c, d;
キャスト
変数は互いに型を変換して使うことができます。これを cast (キャスト)と呼びます。例えば、
int a ;
float b = 1.5 ;
a = (int) b;
と記述すると変数 a には 1 が代入されます。浮動小数点数 1.5 が小数点以下を切り捨てて int型(整数) 1 にキャスト(型変換)されて代入されるわけです。キャストはこのように
変数 = (変換したい型名) 変数 もしくは 定数 ;
というふうに記述しますが、キャスト変換を記述しなくとも自動的に型変換が行われる場合もあります。しかしその場合もほとんどはコンパイラ任せですのでキャストは上記のように明治的に記述するようにいたしましょう。
配 列
同じデータ型を続けて複数個作成して1つの変数名で管理するもの。各データには0からはじまる続き番号が付けられます。各データ型に付けられた番号は0から始まりますのでデータ数10個の配列のそれぞれの番号は0〜9となります。配列の各データのことを要素と呼び、各要素に付けられた番号を添字と呼びます。英語では index と呼びます。
なお文字列を表す char型配列では文字列の終わりを表す 0 というデータを格納する要素が必要になりますので配列の要素数は文字数+1となります。またこの場合の文字数とは英語などの1バイト文字での文字数のことで日本語などの2バイト文字は英語の場合に比べると2倍の要素数が必要となります
#define
#include と同じプリプロセッサです。プリプロセッサとはコンパイルの前に行われる作業を指示するもののことです。
#define MAXLENGTH 100
などど記述するとソースコード中で MAXLENGTH と記述された部分がコンパイルされる前にすべて 100 に置き換えられます。このように MAXLENGTH などの文字列このことを記号定数と呼び、普通はすべて大文字で書くことになっています。なお、#include プリプロセッサと同じく最後にセミコロン ; は付けません。注意しましょう
列挙型
割とプログラムの中で使われるので一応紹介しておきます。
enum typeName { WHITE, SILVER, BLACK, RED, GREEN } variableName ;
と記述します。最初の enum はこれから列挙型を宣言しますという意味を表しています。続く typeName で列挙型で作った新しいデータ型に名前を付けています。つまり列挙を使って新しい型を作ったことになります。型名はもちろん任意の名前で結構です。続けてブロック { } 内にカンマで区切って記号定数を記述していきます。最後にブロック} の後に変数名 variableNameを宣言します。この変数名も任意の名前で結構です。
この列挙型では記号定数(列挙型の場合には正確には列挙定数と言いますが)の部分に自動的に 0, 1, 2, 3, 4 という数字が順番に充当されていきます。また、
enum typeName { WHITE, SILVER = 4, BLACK, RED, GREEN } variableName ;
と記述した場合には WHITE から順番に 0, 4, 5, 6, 7 という数字が充当されます
列挙定数もまったく任意の文字で結構ですがやはり大文字で表すのが慣習となっています。
話だけではいまひとつ理解するのは難しいとは思いますが、例えば switch 文の条件式にこの列挙型を使うなどが考えられます。プログラムの中に割と出て来るので一応述べておくことにしました。
構造体
私がはじめて読んだ C++ という最硬派のオブジェクト指向言語の入門書ではオブジェクトのことを「構造体に、それに関係する関数を付け足したもの」という説明がされていました(言葉はもっと丁寧だった思いますが)。これは歴史的にみて間違いです。構造体のできる以前に smalltalk という言語でオブジェクトが使われはじめていたのです。しかしこの説明はオブジェクトの説明するうえで非常に便利な説明です。ですので次回からはじめるつもりの「learn ObjC 2.0」でもこの説明のしかたを採用しようと思います。そこで、この「learn C」のしめくくりとして構造体の説明をしたいと思います。
構造体は今までに出て来たあらゆるデータ型を構造体という新しい型の中のメンバーとして登録して1つの型にまとめたものです。各データには構造体のメンバーとしてアクセスできます。登録できるデータ型の数に制限はありません。
一般のデータ型では、データ型名 変数名 ; という宣言で使いはじめることができますが。構造体はあなた自身が作る新しいデータ型です。まずはそのデータ型としての形を決めなければなりません。このような作業(行為)のことを普通は定義というと思うのですが C言語ではこの作業のことも 宣言 と言います。今後文章として宣言と定義の言葉の使い方で少しややこしくなりますが適宜に、もしくは適当に解釈して読んでください。
構造体の宣言
struct 構造体名 {
char name [ 30 ] ;
char address [ 100 ] ;
char phoneNumber [ 20 ] ;
char email [ 50 ];
} ;
構造体名のところは任意に命名できます。上記の例を見てわかるとおりこれはアドレス帳です。addressBook と名付けることにします。ブロック文 } の後にセミコロン ; が必要なことに注意してください。
この新しく作った構造体の変数の宣言をしてみましょう。
struct addressBook person ;
// 構造体 addressBook 型の変数 person を宣言
struct addressBook person1, person2, person3 ;
// 構造体 addressBook 型の変数を1度に複数宣言
struct addressBook person [ MAXLENGTH ] ;
// 構造体 addressBook 型の配列を宣言。MAXLENGTH は記号定数でこの場合100を表している
この宣言方法では他のデータ型の変数宣言に比べると先頭の struct がジャマなように感じます、そこで typedefというキーワードを用います。
typedef struct 構造体名 {
char name [ 30 ] ;
char address [ 100 ] ;
char phoneNumber [ 20 ] ;
char email [ 50 ];
} 構造体名 ;
このように宣言すると、構造体の変数宣言も
addressBook person ;
addressBook person1, person2, person3 ;
addressBook person [ MAXLENGTH ] ;
という具合に簡略化できます。
構造体の各メンバ変数には
addressBook . name = "Yamada Hanako" ;
addressBook . address = "Osaka Japan" ;
というようにドット演算子 . を使ってアクセスします。
なお typedef キーワードを簡単に説明すると
typedef int newName ;
と記述することによって
newName a ; という宣言で、
int a ; という宣言と同じ意味になります。
newName には変数や関数の命名規則に従った任意の文字列が使えます。
サンプルコード
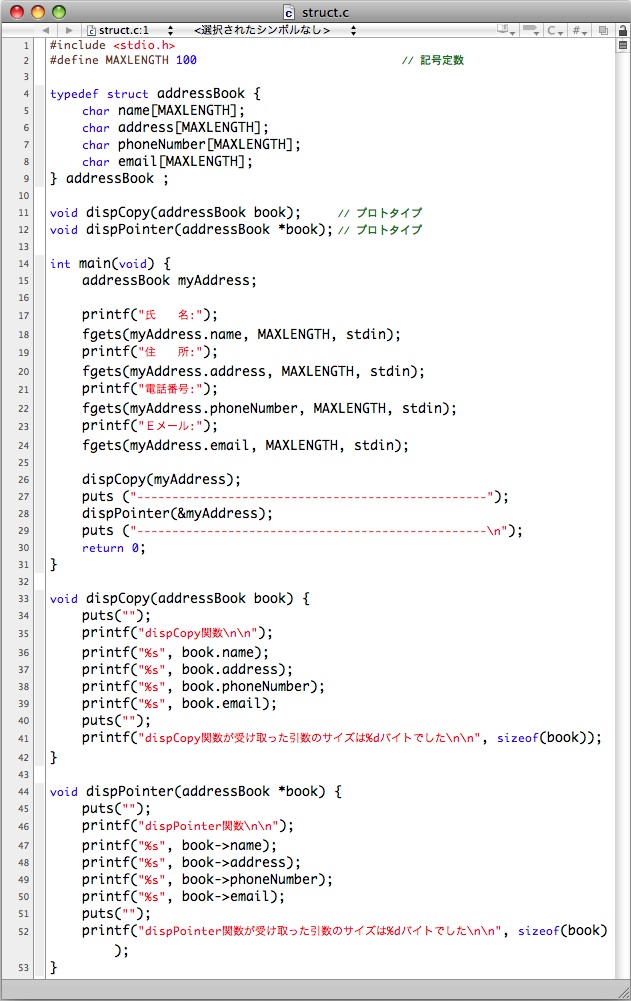
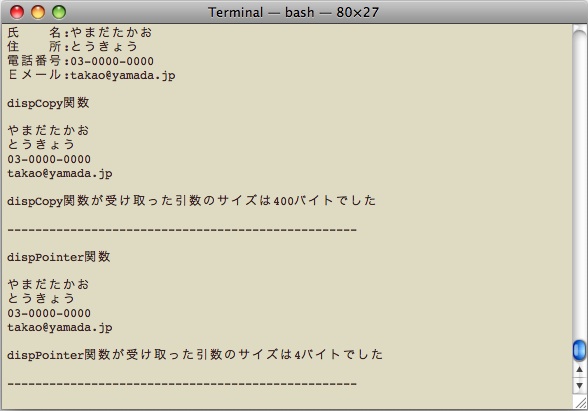
struct.c
実行画面
コード説明
2行目で記号定数 MAXLENGTH を100にしています。4〜9行目の構造体の宣言でメンバー変数のすべてでこの記号定数を使っています。11行目と12行目は後から出て来る自作関数のプロトタイプです。
main( )関数のfgets( )関数ではキーボードから入力された文字列を構造体addressBook型のmyAddress変数の各メンバー変数へ直接格納するようにしています。18行目・20行目・22行目・24行目で変数名(myAddress) . メンバー変数名(name, address, phoneNumber, emailなど)というように 変数名 . メンバー変数名 で構造体の中のメンバ変数にアクセスできます。この . を ドット演算子 と呼びます。
また fgets( )関数の第2引数にも MAXLENGTH記号定数を使っています。
26行目のdispCopy( )関数では構造体のmyAdoress変数のコピーを引数として渡しています。このように引数としてコピーを渡すことを値渡しとも呼びます。それに対して28行目の dispPointer( )関数ではmyAddress変数のポインター(アドレス)を渡しています。このように引数としてポインターを渡すことを参照渡しとも呼びます。参照渡しの場合には &変数名 と変数名の前に & を付けることでアドレスを渡すことができます。
引数をコピーで受け取った dispCopy( )関数では構造体の各メンバ変数へドット演算子 . でアクセスします。それに対して引数をポインターで受け取った dispPointer( )関数ではメンバ変数にアクセスするのに アロー演算子 -> を使います。
最後に各関数で sizeof演算子 を使って受け取った引数の使用メモリーサイズを調べています。sizeof演算子は引数内の変数や定数の使用メモリーサイズをバイト単位で返します。sizeof( ) という形からヘッダファイルの #include が必要な関数のように思われますが C言語で最初から用意されている予約語の1つです。
お疲れさまでした。これで「 learn C 」全6回を終了したいと思います。読んで頂いてありがとうございました。
続けて「 learn ObjC 2.0 」を書いていきたいと思います。タイトルからも分かるように Leopard から採用された Objective-C 2.0 の説明をまた懲りずにターミナル上で行いたいと思います。あくまでも基本的な事柄だけの簡単なものになると思います。
|
|
|

